
Announcement
Layman Tutorials for Data Science site Annalyzin is now called Algobeans!
We’re creating a new mailing list to deliver tutorials to your inbox. If you’d like to be included, sign up:
![]()
If you’re already subscribed, signing up to this new mailing list will remove you from the old one. No spam.
Have you ever wondered about the difference between red and white wine? 🍷
Some assume that red wine is made from red grapes, and white wine is made from white grapes. But this is not entirely true, because white wine can also be made from red grapes, though red wine cannot be made from white grapes.
The main difference between red and white wine is in how the grapes are fermented. To make red wine, grape juice is fermented along with the grape skin, the source of red pigments. For white wine, the juice is fermented without the skin. Presence of grape skin in the fermentation process is likely to affect not only the color of the wine, but also its chemical makeup. This means that, without looking at the color of the wine, we can possibly infer whether a wine is red or white, based on levels of its chemical compounds.
To check our hypothesis, we can use a technique called k-Nearest Neighbors (k-NN).
Definition
k-NN is one of the simplest methods in machine learning. It classifies a data point based on how its neighbors are classified. So if we are guessing the color of a particular wine, we can refer to the color of other wines that have the most similar chemical makeup (i.e. neighbors).
Besides classification into groups, k-NN can also be used to estimate continuous values. To approximate a data point’s value, k -NN takes the aggregated value of its most similar neighbors.
An Illustration
Data on the chemical makeup of red and white variants of Portuguese Vinho Verde wine was obtained from Cortez et al., 2009. We can plot the 1599 red and 4898 white wines with 2 chemical compounds, chlorides and sulfur dioxide, as the axes:

Figure 1. Levels of chlorides and sulfur dioxide in red wines (in red) and white wines (in black).
Minerals such as sodium chloride (i.e. table salt) are concentrated in grape skin, hence more of these get infused into red wines. Grape skin also contains natural anti-oxidants that keep the fruit fresh. Without it, white wines require more sulfur dioxide, which serves as a preservative. For these reasons, red wines are clustered at the bottom-right of the plot, while white wines are at the top-left.
To deduce the color of a wine with specified levels of chloride and sulfur dioxide, we can refer to the known colors of neighboring wines with similar quantities of both chemical compounds. By doing this for each point in the plot, we can draw decision boundaries distinguishing red from white wines:
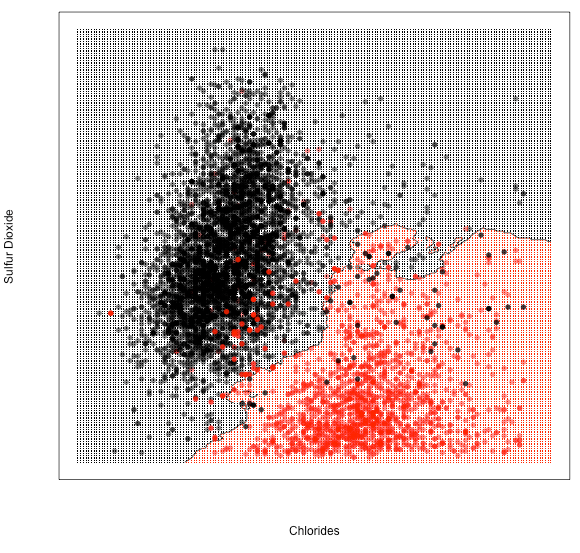
Figure 2. Predicted classifications of wine color using k-NN. Unknown wines inside the red boundary would be predicted as red wine, whereas those in the black boundary would be predicted as white wine.
Using these decision boundaries, we can predict a wine’s color with over 98% accuracy. Let us take a look at how these boundaries are inferred from nearest neighbors.
Technical Explanation
Recall that k-NN classifies a data point based on how its neighbors are classified. This means if a data point is surrounded by 4 red points and 1 black point, that data point is likely a red point by majority vote:

Figure 3. A data point is classified by majority votes from its 5 nearest neighbors. Here, the unknown point would be classified as red, since 4 out of 5 neighbors are red.
The k in k -NN is a parameter that refers to the number of nearest neighbors to include in the majority voting process. In the above example, k equals to 5. Choosing the right value of k is a process called parameter tuning, and is critical to prediction accuracy.
| k = 3 | k = 17 | k = 50 |
|
|
 |
 |
| 98.2% accuracy | 98.6% accuracy | 97.8% accuracy |
| Overfit | Ideal fit | Underfit |

Table 1. Comparison of model fit using varying values of k.
If k is too small, data points would match immediate neighbors only, amplifying errors due to random noise. If k is too large, data points would try to match far flung neighbors, diluting underlying patterns. But when k is just right, data points would reference a suitable number of neighbors such that errors cancel out to reveal subtle trends in the data.
To achieve the best fit and lowest error, the parameter k can be tuned by cross-validation. In our binary (i.e. two class) classification problem, we can also avoid tied votes by choosing k to be an odd number.
Apart from classifying data points into groups, k-NN can also be used to predict continuous values, by aggregating the values of the nearest neighbors. Instead of treating all neighbors equally and taking a simple average, the estimate could be improved by taking a weighted average, where we pay more attention to the values of closer neighbors than those further away, since closer neighbors are more likely to reflect a data point’s true value.
Anomaly Detection
k-NN is not limited to merely predicting groups or values of data points. It can also be used in detecting anomalies. Identifying anomalies can be the end goal in itself, such as in fraud detection. Anomalies can also lead you to additional insights, such as discovering a predictor you previously overlooked.
The simplest approach to detecting anomalies is by visualizing the data in a plot. In Figure 2 for instance, we can see immediately which wines deviate from their clusters. However, simple 2-D visualizations may not be practical, especially when you have more than 2 predictor variables to examine. This is where predictive models such as k-NN come in.
As k-NN uses underlying patterns in the data to make predictions, any errors in these predictions are thus telltale signs of data points which do not conform to overall trends. In fact, by this approach, any algorithm that generates a predictive model can be used to detect anomalies. For instance, in regression analysis, an outlier would deviate significantly from the best-fit line.
In our wine data, we can examine misclassifications generated from k-NN analysis to identify anomalies. For instance, it seems that red wines that get misclassified as white wines tend to have higher-than-usual sulfur dioxide content. One reason could be the acidity of the wine. Wines with lower acidity require more preservatives. Learning from this, we might consider accounting for acidity to improve predictions.
While anomalies could be caused by missing predictors, they could also arise due to insufficient data for training the predictive model. The fewer data points we have, the more difficult it would be to discern patterns in the data. Hence, as it is important to ensure an adequate sample size.
Once anomalies have been identified, they can be removed from the datasets used to train predictive models. This will reduce noise in the data, thus strengthening the accuracy of predictive models.
Limitations
Although k-NN is simple and effective, there are times when it might not work as well.
Imbalanced classes. If there are multiple classes to be predicted, and the classes differ drastically in size, data points belonging to the smallest class might be overshadowed by those from bigger classes, increasing their risk of misclassification. To improve accuracy, we could use swap majority voting in favor of weighted voting, whereby the class of closer neighbors are weighted more heavily than ones further away.
Excess predictors. If there are too many predictors to consider, it would be computationally intensive to identify and process nearest neighbors across multiple dimensions. Moreover, some predictors could be redundant as they do not improve prediction accuracy. To resolve this, we can use dimension reduction techniques to extract only the most powerful predictors for analysis.
Did you learn something useful today? We would be glad to inform you when we have new tutorials, so that your learning continues!
Sign up below to get bite-sized tutorials delivered to your inbox:

Copyright © 2015-Present Algobeans.com. All rights reserved. Be a cool bean.
Data credits: P. Cortez, A. Cerdeira, F. Almeida, T. Matos and J. Reis. Modeling wine preferences by data mining from physicochemical properties. In Decision Support Systems, Elsevier, 47(4):547-553. ISSN: 0167-9236.

I am regular reader, how are you everybody? This article posted at this
website is actually nice.
LikeLike