
Suppose you have the following set of sentences:
- I eat fish and vegetables.
- Fish are pets.
- My kitten eats fish.
Latent Dirichlet allocation (LDA) is a technique that automatically discovers topics that these documents contain.
Given the above sentences, LDA might classify the red words under the Topic F, which we might label as “food“. Similarly, blue words might be classified under a separate Topic P, which we might label as “pets“. LDA defines each topic as a bag of words, and you have to label the topics as you deem fit.
There are 2 benefits from LDA defining topics on a word-level:
1) We can infer the content spread of each sentence by a word count:
Sentence 1: 100% Topic F
Sentence 2: 100% Topic P
Sentence 3: 33% Topic P and 67% Topic F
2) We can derive the proportions that each word constitutes in given topics. For example, Topic F might comprise words in the following proportions: 40% eat, 40% fish, 20% vegetables, …
LDA achieves the above results in 3 steps.
To illustrate these steps, imagine that you are now discovering topics in documents instead of sentences. Imagine you have 2 documents with the following words:
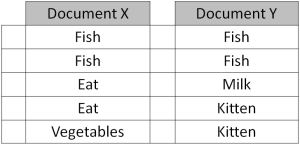
Step 1
You tell the algorithm how many topics you think there are. You can either use an informed estimate (e.g. results from a previous analysis), or simply trial-and-error. In trying different estimates, you may pick the one that generates topics to your desired level of interpretability, or the one yielding the highest statistical certainty (i.e. log likelihood). In our example above, the number of topics might be inferred just by eyeballing the documents.
Step 2
The algorithm will assign every word to a temporary topic. Topic assignments are temporary as they will be updated in Step 3. Temporary topics are assigned to each word in a semi-random manner (according to a Dirichlet distribution, to be exact). This also means that if a word appears twice, each word may be assigned to different topics. Note that in analyzing actual documents, function words (e.g. “the”, “and”, “my”) are removed and not assigned to any topics.
Step 3 (iterative)
The algorithm will check and update topic assignments, looping through each word in every document. For each word, its topic assignment is updated based on two criteria:
- How prevalent is that word across topics?
- How prevalent are topics in the document?
To understand how these two criteria work, imagine that we are now checking the topic assignment for the word “fish” in Doc Y:

- How prevalent is that word across topics? Since “fish” words across both documents comprise nearly half of remaining Topic F words but 0% of remaining Topic P words, a “fish” word picked at random would more likely be about Topic F.

- How prevalent are topics in the document? Since the words in Doc Y are assigned to Topic F and Topic P in a 50-50 ratio, the remaining “fish” word seems equally likely to be about either topic.

Weighing conclusions from the two criteria, we would assign the “fish” word of Doc Y to Topic F. Doc Y might then be a document on what to feed kittens.
The process of checking topic assignment is repeated for each word in every document, cycling through the entire collection of documents multiple times. This iterative updating is the key feature of LDA that generates a final solution with coherent topics.
Example applications of topic modeling:
Generating an Automated Biography for a Country with News Articles
Did you learn something useful today? We would be glad to inform you when we have new tutorials, so that your learning continues!
Sign up below to get bite-sized tutorials delivered to your inbox:

Copyright © 2015-Present Algobeans.com. All rights reserved. Be a cool bean.

Very helpful, thanks.
LikeLiked by 1 person
can you please explain with an example from 1st iteration to last iteration in more detailed way…
LikeLike
i am so happy and thank god for being here and read your Post, still the best that i have read ever.
LikeLike
sorry I am a newbie in the area of topic modeling, I would ask you , is there any possibility to define the topics in beforehand?
for instance to have some topics, named as soccer, tennis, etc.
LikeLike
Good one Annalyn. Next time, I need to teach a group of students about this topic. I am going to use your example. I am sure they will understand the topic better than doing it with all Math! 🙂
By the way, I know you have written a book recently compiling all the topics in a non-math way. Is there a way the book be made available free for educational purposes. I see it is on sale on amazon.
LikeLike
Hi Annalyn,
Thanks for the explanation on this topic.
For the example on How prevalent is that word across topics, since each word in the 2 documents is assigned to a random topic, how come the 3 ‘fish’ words happen to be assigned to the same topic F?
Thanks
LikeLike
Hi Allen, you’re most welcome. The assignment of the 3 ‘fish’ words was made all to be F for the ease of explanation. You can also view the assignments as occurring in the later stages of iteration, where topics are assigned more accurately. You are right that at the beginning, topics would be assigned more randomly – or according to a dirichlet distribution to be exact.
LikeLike
Thanks for your reply Annalyn. It makes sense now. Though I have another question now.
Suppose by chance, in the first iteration, the majority of ‘fish’ words are assigned to the P topic, how can LDA correct the error over time? To me LDA feels very different from other ML algorithms where there is an cost function to measure the correctness of your model at every iteration. So for LDA, how do we know if the current iteration is better than the previous one?
Thanks, Allen
LikeLiked by 1 person
Allen, good question! To prevent these errors in the first place, LDA requires us to set initial parameters that determine topic assignments. These parameters are called alpha and beta. In a symmetric dirichlet distribution, high alpha means that all your documents contain most topics (as opposed to documents containing a few or just a single topic). High beta means that all your topics contain most of the words in your corpus. LDA works towards optimizing topic assignments based on these parameters through the iterative process.
LikeLiked by 1 person
Thanks Annalyn. Really appreciate your prompt reply. I kind of get your point and will dig into the details of the LDA implementation to understand how it works exactly. Thanks. Allen
LikeLike
Thanks, Annalyn.
I learned something from you.
LikeLiked by 1 person
You’re most welcome Ted.
LikeLike
Very crisp and simple, for a layman. Thanks Annalyn!
LikeLike
Thanks Ahsaas, glad you found it useful.
LikeLike
Very helpful artical Annalyn. Thanks for posting.
LikeLike
Glad you found it helpful, James.
LikeLike