
Outliers can generally be detected by algorithms used for predictions. Examples include algorithms for clustering, classification and association rule learning.
To illustrate, let’s run through an example with the k-nearest neighbor (kNN) clustering algorithm.
First, you have to train the kNN algorithm by providing it with data clusters you know to be correct. Take, for instance, geographical clusters of liberals and conservatives:
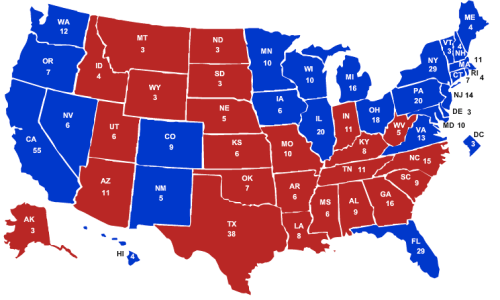
Presidential Election Interactive Map and History of the Electoral College
Imagine that you do not know whether CO is blue or red. You only have information on its surrounding states. Hence, you are only able to tell the algorithm that UT, WY, NE, KS, OK are red states, and that NM is a blue state. Based on this information, you want the algorithm to guess whether CO is red or blue.
The kNN algorithm deduces the political leaning of CO based on its k nearest neighbours. If k = 6, it identifies the 6 states nearest to CO, and then finds out whether the majority of those states are red or blue.
Since the 6 states nearest to CO are its 6 adjacent states mentioned above, and 5 of those states are red, the kNN algorithm would classify CO as a red state.
However, according to the electoral map above, CO is in fact a blue state.
Therefore, based on its susceptibility to incorrect classification, we might then label CO as an outlier. In other words, outliers are those data points which predictive algorithms consistently classify into incorrect categories.
In addition to data mining algorithms, basic approaches for outlier detection could also be used for a first-cut sensing:
- Use visualizations like scatterplots and histograms
- Identify data points that are more than 1.5 times the interquartile range above the third quartile or below the first quartile
Did you learn something useful today? We would be glad to inform you when we have new tutorials, so that your learning continues!
Sign up below to get bite-sized tutorials delivered to your inbox:

Copyright © 2015-Present Algobeans.com. All rights reserved. Be a cool bean.
