
In most developed cities, it is common to see cuisine from different cultures lining the same street. While each dish has its own distinct taste and texture, perhaps there is more similarities than we acknowledge—to a Spaniard, dim sum might be nothing more than Chinese tapas.
The question is, how can we systemically identify analogous food items across cultures?
Given that similar food items would be described similarly, just as how dim sum and tapas would both be ‘snacks‘ served on ‘small plates‘, we can start by examining the words used to describe food.
An Illustration
Using a word embedding model trained on approximately 6 billion words from Wikipedia and news articles, we can examine abstract relationships between food items. For example, to find the equivalent of American Tartare in Japan, we can key in this equation:

The word embedding model would then search for the item that is most like Tartare in Japan but not found in America, which turns out to be Sashimi.

Here are more examples:

Apart from finding analogous items, embeddings can retain semantic meaning, allowing us to form other equations such as:

Going further, we can use similarity scores to deduce how distinct each word is relative to other words. Using these similarity scores, we can plot the words on a map, with more similar words being closer to each other. For example, the following is a word map generated by shortlisting the top 17 words most similar to Flatbread:

We can observe several clusters in the word map, which we delineate below in different colors:
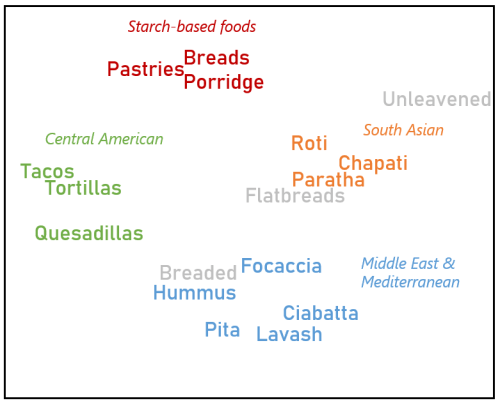
.
Technical Explanation
Word embedding techniques take a large corpus of text and assigns each unique word a position on an abstract map. These positions are also known as vectors or embeddings. Once we have all the words on the map, we can use the distance between words as an indicator of how similar they are—words with similar meanings are positioned closer together.
One popular type of word embedding technique is GloVe, short for Global Vectors for Word Representation. For a given text corpus, GloVe will iterate through every word and count the number of times it appears alongside other neighboring words. Neighboring words provide information on the context in which the target word is used, so that if words have similar contexts, they would be positioned closer together on the resulting map.
GloVe follows these steps to calculate word embeddings:
Step 0: Define the size of a target word’s neighborhood, also called window size.
Step 1: For the target word, count the number of times other words appear alongside the target word in its neighborhood. Words which are farther away from the target would be given a smaller weight.
Step 2: Repeat Step 1 for every word in the corpus
To illustrate, a simplified example is shown in Figure 3, based on two sentences and two target words:

In this example, we use a window size of two, accounting for up to two words before and after the target word. Typical window sizes range from five to 20—the larger text corpus, the smaller the required window size.
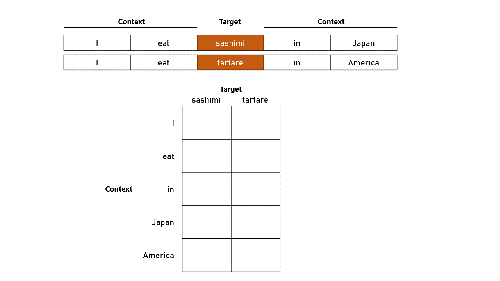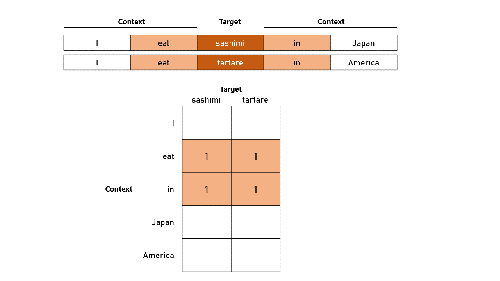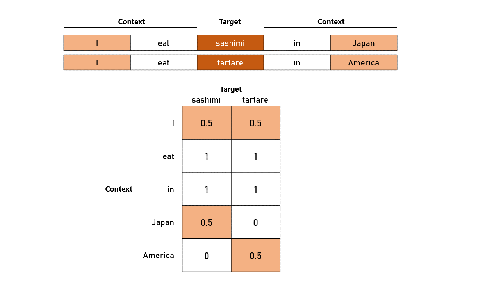
If we want to check how similar dumpling is to ravioli, we set those two words as our targets, and compare their neighboring words. First, we count the words to their immediate left and right, followed by the words farther away with progressively smaller weights. As we complete our counts, we are simultaneously forming a series of numbers, which would eventually become the embedding that would represent the target word.
Based on our two sentences, the final embeddings for our target words are identical except for the last two numbers:
sashimi: [0.5, 1, 1, 0.5, 0]
tartare: [0.5, 1, 1, 0, 0.5]
If we repeat this process for a larger variety of sentences, we might find our target words sharing even more common neighbors, such as ‘wrapped’, ‘fillings’, ‘juicy’. This would suggest that our target words are closely related because they share a large overlap in context. The only exception here would be counts relating to countries, which correspond to the last two numbers in their embeddings above. This discrepancy thereby enables us to distinguish dumplings from ravioli based on their countries of origin.
In this post, we learned how GloVe works; it is a count-based method for deriving word embeddings. Word counts are a way of distilling patterns in the word corpus, so GloVe is essentially an unsupervised machine learning technique. We can also derive word embeddings through supervised learning, in which we predict what a word could be based on the surrounding context words. In this case, we would iteratively improve on the set of embeddings by minimizing the prediction loss. One example of a supervised word embedding algorithm is word2vec.
.
Limitations
Embeddings are useful for extracting meaningful relationships between words. However, the human language is creative and unstructured, so any algorithm that tries to squeeze it into a fixed mold would inevitably trip up at some point. Here are a few scenarios where the performance of word embeddings would lapse:
- Words that have multiple meanings. Since each word is only allocated a single embedding, a word that has different meanings depending on context might have an embedding that is ambiguous, or that skew towards the context that is most used in the corpus from which it was derived. In our above example, if we had searched for top words most similar to apple, we would get:

As our corpus comprised news articles, the word apple would have likely been associated with media reports on one of the world’s most valuable company. If we had wanted to refer to the fruit, one quick fix would be to declare a negative association with technology:

- Words that change their meaning when used in a phrase. A living room is not a room that is alive, and a flea market is not a place that sells fleas. Some phrases are more than a simple sum of their words, so to improve accuracy, they need to be represented by their own embeddings. An obvious drawback of analyzing all possible phrases would be a surge in vocabulary size. To reduce computation burden, we can narrow our selection of phrases to those comprising infrequent words, so as to exclude terms like “and the” or “this is”. We can also refer to the titles of Wikipedia pages to account for common phrases, and even proper names like New York.
Did you learn something useful today? We would be glad to inform you when we have new tutorials, so that your learning continues!
Sign up below to get bite-sized tutorials delivered to your inbox:

References
- Jupyter Notebook: https://github.com/algobeans/Word-Embeddings
- Pre-trained model is from: https://nlp.stanford.edu/projects/glove/
(glove-wiki-gigaword-300) Wikipedia 2014 + Gigaword 5 (6B tokens,400K vocab, uncased), 376 MB, 400,000 vectors - Model was assessed through this API: https://github.com/RaRe-Technologies/gensim-data
